Искусственный интеллект: мифы и реальность


Чем больше мы становимся цифровым обществом, тем большее влияния не нашу жизнь начинает оказывать искусственный интеллект (ИИ). На тему ИИ написано огромное количество статей, обзоров, выступлений и уже, наверное, скоро ни один разговор без этой темы обходиться не будет.
Но давайте немного раскроем эту тему, разберемся, что к чему, и ответим себе на несколько вопросов:
- что же такое ИИ;
- какие ИИ есть;
- насколько ИИ может быть полезен или вреден бизнесу.
Многие встречались на сайтах для подтверждения «что вы человек» с тестом CAPTCHA. Данный тест был разработан университетом «Карнеги – Меллона» в 2000 году и основывается на известном тесте Тьюринга. Основная идея теста – предложить пользователю такую задачу, которая с легкостью решается человеком, но крайне сложна и трудоемка для компьютера. Таким образом в интернете уже более 20 лет различают, кто же получает доступ к данным, компьютер или человек.
Но тема искусственного интеллекта была поднята задолго до XXI века. Алан Тьюринг в 1950 году в статье, вышедшей в журнале Mind, обратился к вопросам искусственного интеллекта, и его размышления стали толчком к активному развитию информатики кибернетики и логики.
Термин «искусственный интеллект» приобрел антропоморфную окраску исключительно в русском языке, ведь artificial intelligence (AI) в дословном переводе звучит, как искусственное умение рассуждать, и никак именно с когнитивными способностями напрямую не связан. Но несмотря на это возможности некоторых разработок на данный момент очень сильно поражают своими возможностями и результатами.
Я кратко рассмотрю функциональность и архитектуру решений на AI для того, чтобы это перестало быть «волшебным черным ящиком» для многих и немного, может быть, развеет мифы о том, что внедрение ИИ на предприятиях дает бизнесу огромный толчок к развитию.
Рассмотрим небольшую иллюстрацию.
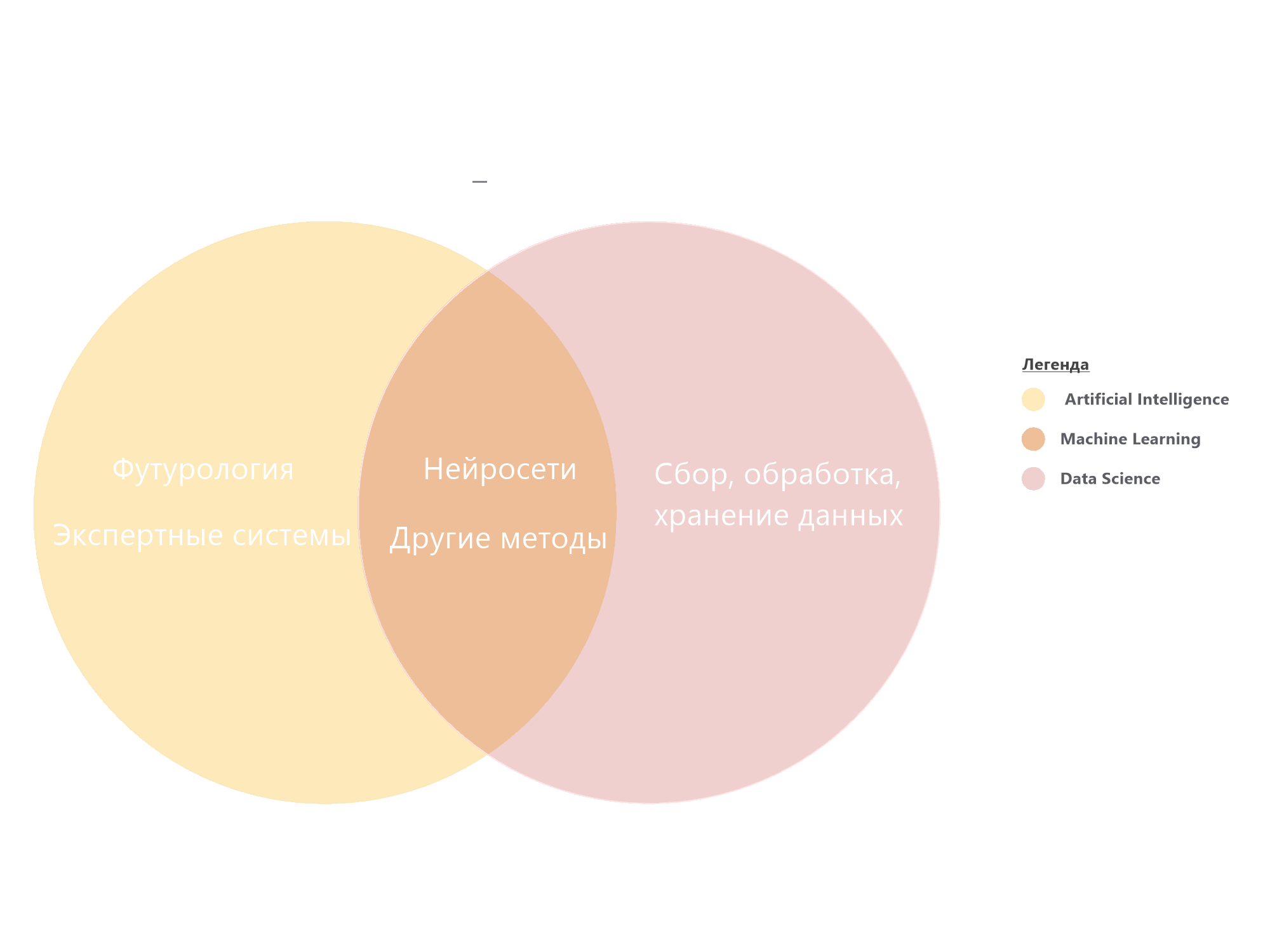
Из нее мы можем сделать вывод, что ИИ (он же AI) является лишь верхушкой айсберга и «под капотом» у него находятся огромные массивы данных, которые должны быть структурированы.
Многие вспомнят тему Big Data, которая 5-10 лет назад активно продвигалась в среднем и крупном бизнесе. Консультанты и интеграторы приходили к собственникам и предлагали строить «озеро данных» или Data Lake. Для построения моделей машинного обучения требуются в разных случаях числовые, текстовые, фото, видео, аудио и иные данные, которые и хранятся в этих «озерах». Дальше все эти данные при помощи специалистов Data Scientists анализируются, создаются алгоритмы и строятся модели. Давайте разберем на примере.
Например, на химическую реакцию, кроме самих вступающих во взаимодействие веществ, влияет множество параметров: температура, влажность, материал емкости, в которой она происходит, и т.д. Химику сложно учесть все эти признаки, чтобы точно рассчитать время реакции. Скорее всего, он учтет несколько ключевых параметров и будет основываться на своем опыте. В то же время на основании данных предыдущих реакций машинное обучение сможет учесть все признаки и дать более точный прогноз.
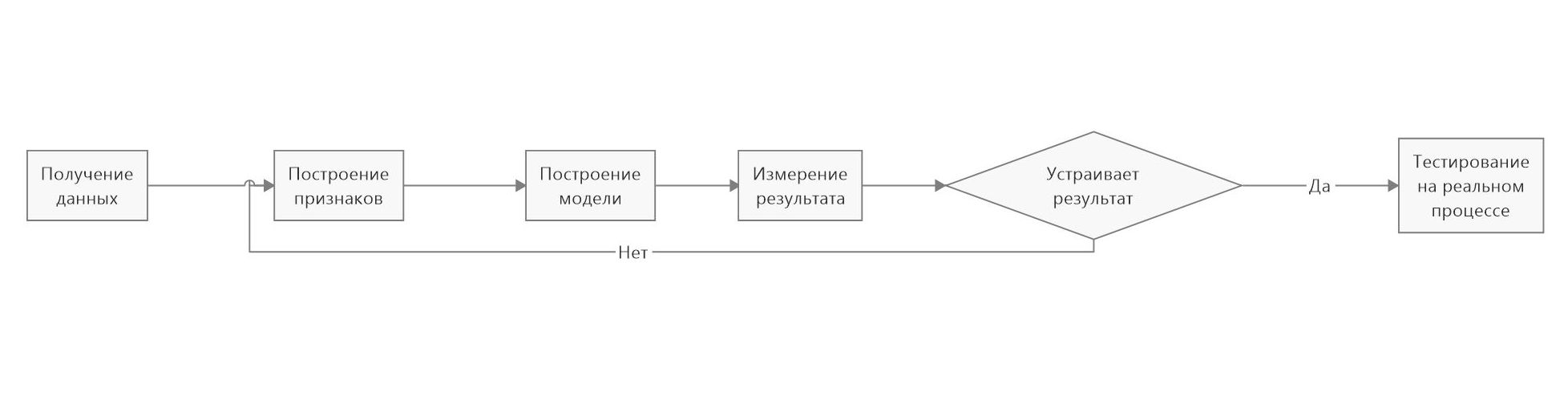
Вот он краткий пример тестирования теории и создания алгоритма на наборе данных.
Но от скучной теории предлагаю перейти к краткому обзору того, что есть на данный момент в публичном использовании. Немного обращаясь назад, скажу, что первым интеллектуальной борьбой с вычислительными средствами на шахматной доске занимался гроссмейстер Г.К. Каспаров (является иноагентом) в 1996-м и в 1997 году. Результаты этих матчей крайне показательны, на мой взгляд, ведь в первом матче Каспаров выиграл со счетом 4:2, а вот уже во втором проиграл со счетом 3,5:2,5. Но в выигрыше Deep Blue есть два фактора:
- по итогам первой партии была проведена крайне серьезная работа и увеличена вариативность;
- Каспарову не давали нотаций матчей, сыгранных ранее суперкомпьютером.
В 2015 году была создана компания OpenAI, которую образовали Илон Маск и Сэм Альтман с целью делать публичный AI продукт, на который не влияют никакие органы власти, и можно избежать концентрации власти. Уже в 2020 году был представлен GPT-3. Но что же скрывается за этими тремя буквами? Generative Pre-trained Transformer – генеративная (т.е. создающая), предварительно обученная платформа на основе трансформер (выпущенная Google в 2017году). По сути, исходя из этого, мы можем понять, что это NLP (Natural Language Processing - обработка естественного языка), то есть, модель, направленная на обработку запросов, составленных путем запросов естественным языком (речью).
В данный момент есть версии 4+, но все мы должны понимать, что у такого «мощного, доступного и бесплатного инструмента», скорее всего, есть и обратная сторона. Все, что выпускается по бесплатной модели и представляется на широкое обозрение, помимо красивой цели помощи людям всего мира, имеет под собой и какую-то выгодную авторам подоплеку.
Своими запросами мы оставляем «цифровой след», позволяя развивать «озеро данных» провайдеру решений, и ускоряем развитие их продуктов, но зачастую массив информации в интернете неоднозначен и может в последующем формировать неправильную точку зрения, что при повальном использовании ИИ может рождать неправильную истину.
Много примеров использования ИИ в замкнутом контуре организаций, например, для аналитики и прогнозирования. Но моделей, которые могут наполниться «всеми знаниями глобальной сети» и потом приносить пользу отдельно взятой организации, на мой взгляд, на данный момент не существует. Сети разряда Flux, DALL·E и Midjourney позволяют генерировать изображения, чтобы использовать их в маркетинговых материалах или презентациях. Обо всех нынешних возможностях ИИ рассказывать можно бесконечно, и при наличии такого запроса можно обращаться к открытым источникам или посещать специализированные мероприятия, например ПИЩЁВКА3D: FOODIGITAL, где теме нейросетей и практике их использования посвящают отдельные секции.
И напоследок предлагаю для примера запросить краткое Summary о портале «Мясной Эксперт».
Отмечу, что особенностью портала «Мясной Эксперт» является то, что более десяти лет его самая содержательная часть – форумы – закрыта от поисковых ботов и программ по анализу и сбору данных. Поэтому весь накопленный за 20 лет работы портала опыт в виде решений от директоров, заведующих производством, инженеров, технологов, технологов – разработчиков, механиков и наладчиков, который собран на форумах, для ИИ недоступен. Это еще раз подтверждает, что ИИ обучается только на той информации, которая ему доступна. Попросите как-нибудь ИИ вывести списком три лучшие компании, производящие вакуумные колбасные куттера для завода мощностью 500 тонн вареной колбасы в сутки. Или назвать три лучших компании, производящие колбасные шприцы для завода мощностью 500 тонн колбасы в сутки. Вы увидите юмористическую, на взгляд специалиста, подборку ответов.
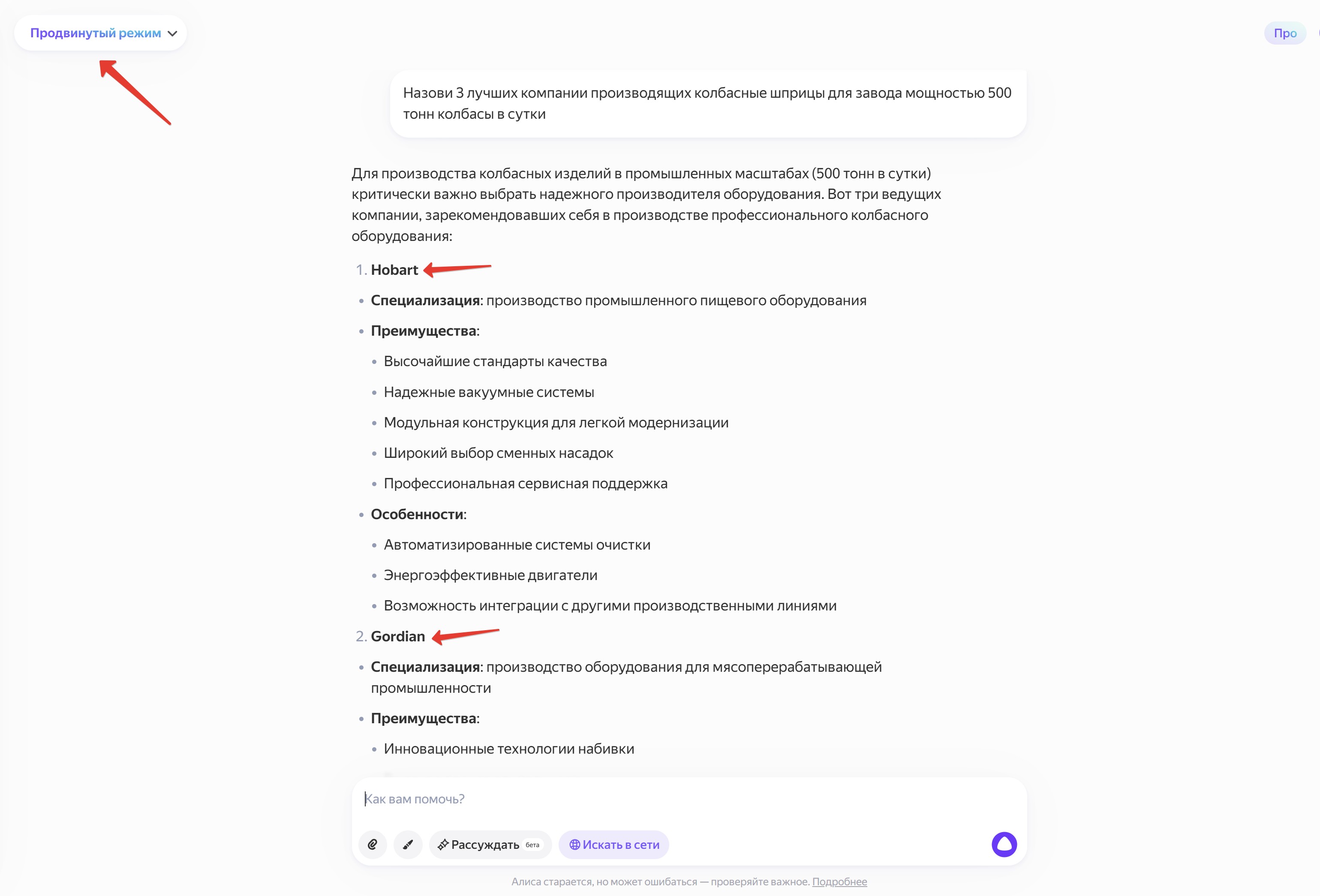
Иногда ИИ вообще может выдать ручные модели. Кроме того, компания «Митиндастри» не производит куттеры марки Laska, как утверждает ИИ, а продает.
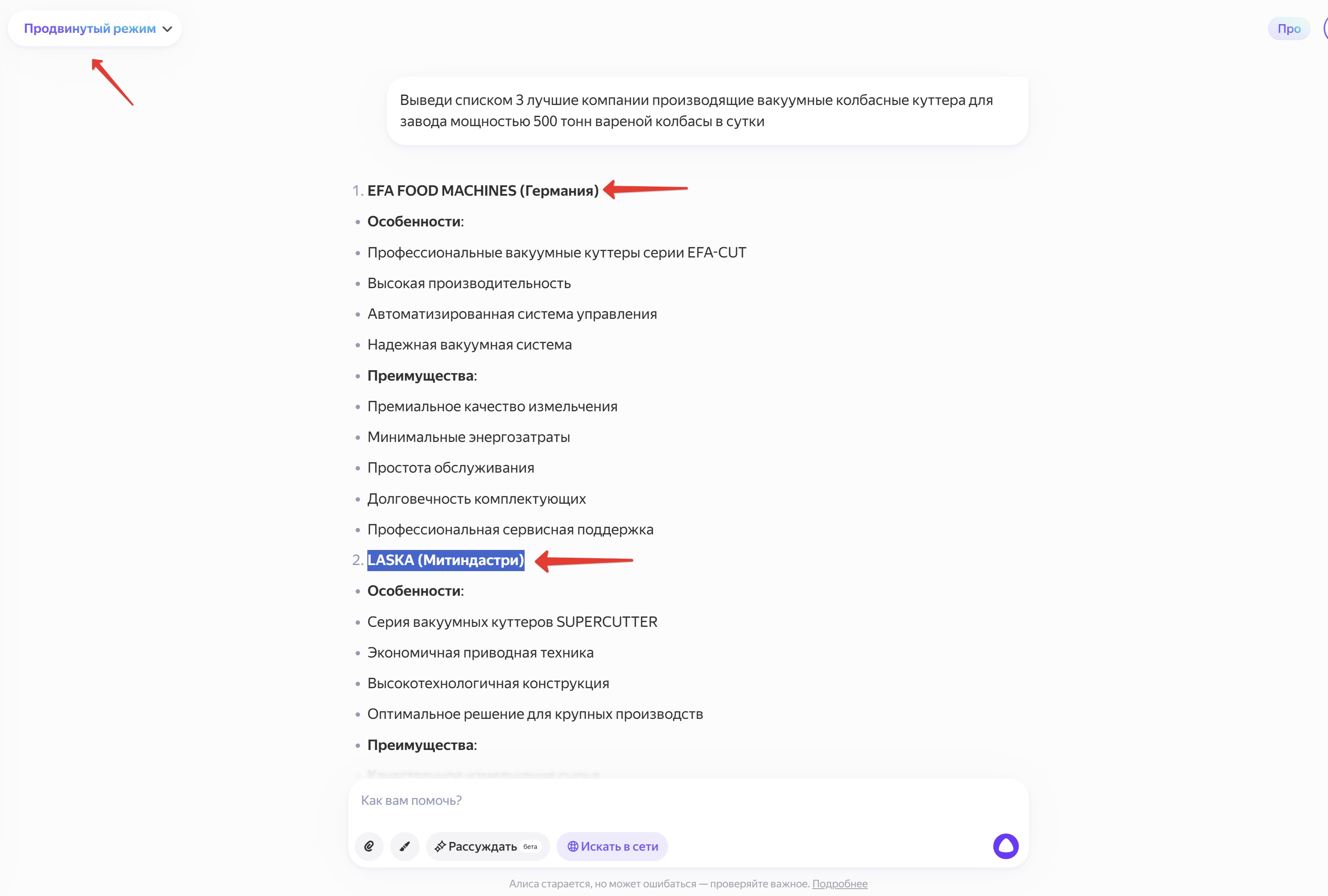
Но ИИ на базе Chat-GPT обучался бегло и не вникая в подробности, по принципу – раз продает, значит, и производит. Не в том озере данных плавает!









Адаптировать аутентичный продукт под реалии современного мясоперерабатывающего предприятия — задача нетривиальная. Еще сложнее при этом не...
Автор материала – Ирина Правская, руководитель направления разработки «Константа ИТ» Материал подготовлен совместно с партнером комьюнити по...
В пятницу, 20 марта 2026 года прошел форум АПК 360, где принимало участие много именитых и известных отраслевых деятелей и...
Материал подготовлен совместно с комьюнити Digital4food и Ириной Правской, руководителем направления разработки «Константа ИТ» И вот момент...
Парейдолия - это распространенная зрительная иллюзия, при которой мозг, стремясь распознать знакомые образы, «дорисовывает» базовые...
День добрый! Вопрос не срочной, но технологический) На завод поступила добавка на...
Коллеги цифровизаторы-интеграторы, айтишники и все умеющие отличать штрих-коды от...
Уважаемые коллеги здравствуйте. скажите пожалуйста кто уже подал заявку на участие в пилотном...
ну или креазот и деготь вам на стол для вашей печени. Фото снято в ноябре 2025...
Здравствуйте. Остаётся щетина после обесволашивания. Пробовали увеличение циклов, замену бил,...
Здравствуйте, уважаемые! Посоветуйте, пожалуйста. Предлагают по 80000 рублей две термокамеры...
Там где Chat-GPT обучался про мясопереработку - я там преподавал.